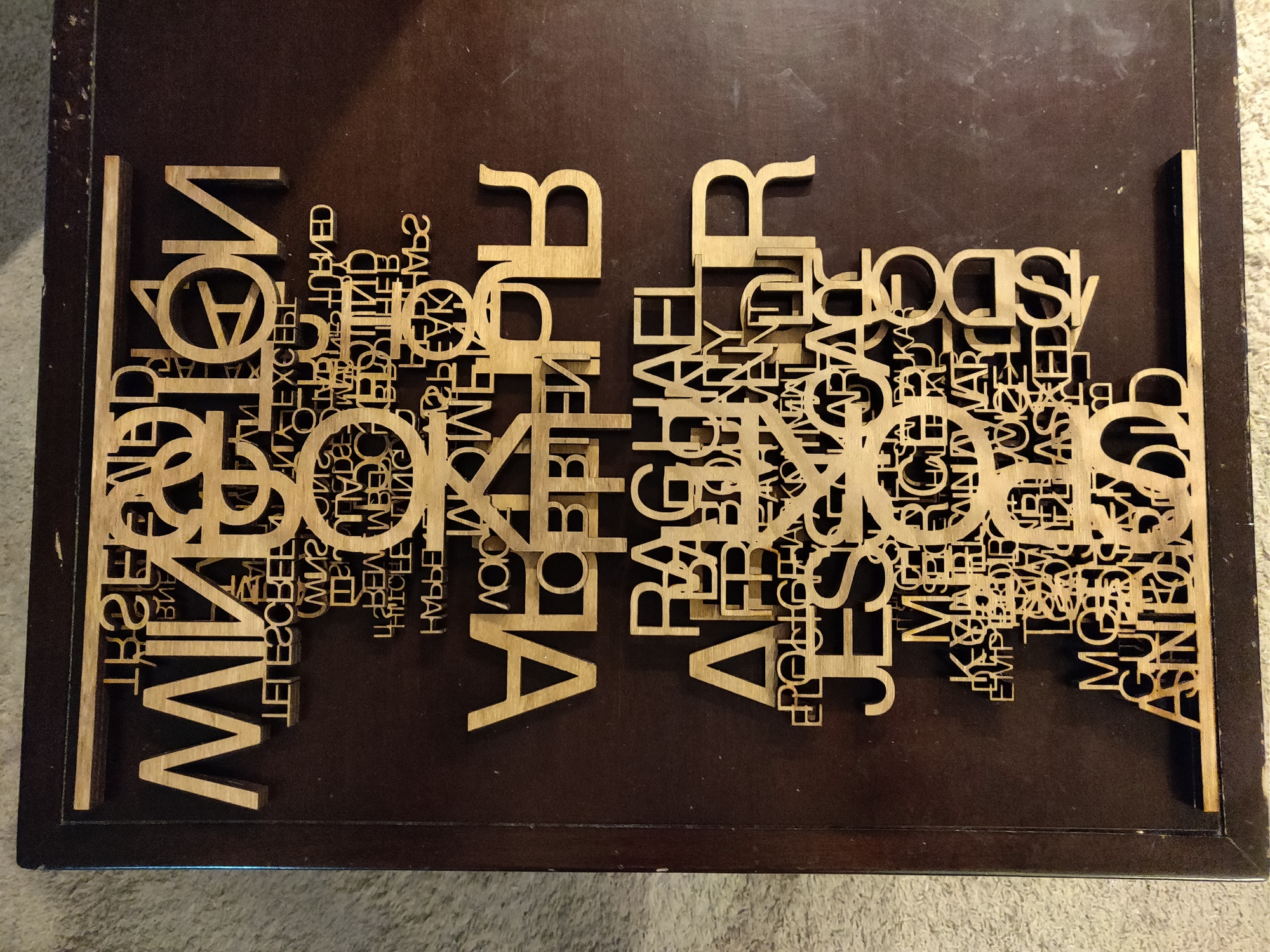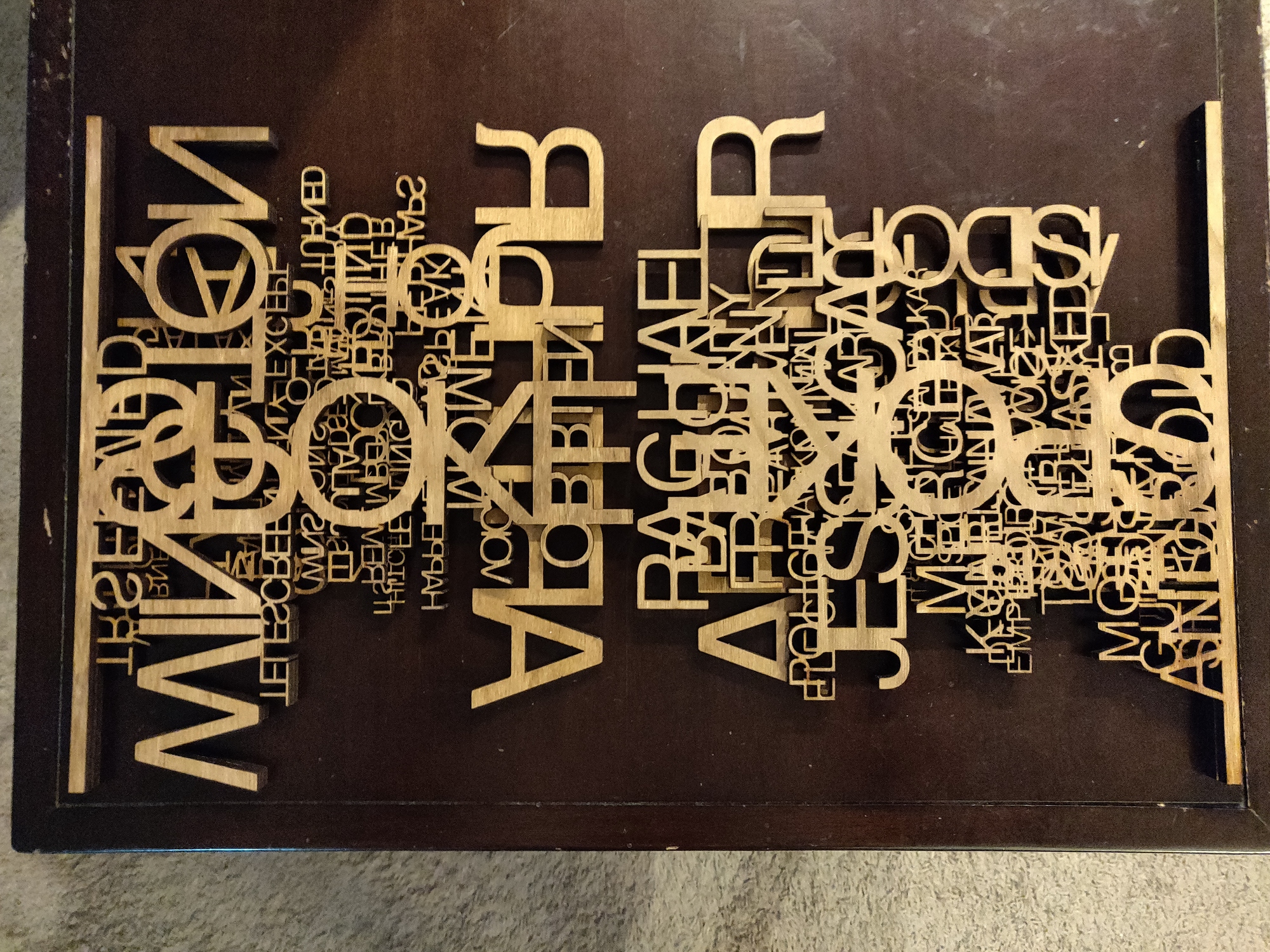|

|
Analysis Tech Art Repositories | |||||||
Author: Brad Cable
library(curl)
library(ggplot2)
library(RColorBrewer)
library(wordcloud)
booklist <- read.csv("books.csv", header=TRUE)
FREQ_X <- 533
#!/usr/bin/env python3
from xml.dom import minidom
import epub, re, sys
if len(sys.argv) == 1:
print("More arguments.")
sys.exit(0)
def search_for_tag(xml_input, tag_name):
if type(xml_input) is bytes:
xml_dom = minidom.parseString(xml_input)
else:
xml_dom = xml_input
ret = []
for i in range(0, len(xml_dom.childNodes)):
xml_child = xml_dom.childNodes[i]
if type(xml_child) is minidom.Element:
if tag_name == xml_child.tagName:
ret.append(xml_child)
else:
ret.extend(search_for_tag(xml_child, tag_name))
return ret
def process_epub(epubfile):
the_epub = epub.open(epubfile, "r")
xml_container = the_epub.read("META-INF/container.xml")
dom_root_rootfiles = search_for_tag(xml_container, "rootfiles")
dom_rootfiles = search_for_tag(dom_root_rootfiles[0], "rootfile")
raw_text = b""
for i in range(0, len(dom_rootfiles)):
data = the_epub.read(dom_rootfiles[i].getAttribute("full-path"))
items = search_for_tag(data, "item")
for item in items:
raw_text += the_epub.read(item.getAttribute("href"))
return raw_text
if __name__ == "__main__":
txt = process_epub(sys.argv[1])
#txt = re.sub(b"<style.*</style>", b"", txt)
txt = re.sub(b"<[^>]+>", b"", txt)
txt = re.sub(b"[^A-Za-z' \n\r\t]+", b"", txt)
txt = re.sub(b"[ \r\n\t]+", b" ", txt)
txt = txt.lower().strip().decode()
words = txt.split(" ")
frequency_count = {}
for word in words:
if word in frequency_count:
frequency_count[word] += 1
else:
frequency_count[word] = 1
print("Word,Count")
for key in frequency_count.keys():
print("{},{}".format(key, frequency_count[key]))
PATH_TO_PYSCRIPT <- file.path(getwd(), "word_freqs.py")
if(!file.exists("english-word-list-total.csv")){
curl_download(
"https://sketchengine.co.uk/wp-content/uploads/word-list/english/english-word-list-total.csv",
destfile="english-word-list-total.csv"
)
}
english_words_frequency <- read.table("english-word-list-total.csv",
header=FALSE, skip=4, sep=";", dec=",", quote="",
col.names=c("Rank", "Word", "Frequency", "Ratio")
)
english_words_frequency <- english_words_frequency[
!is.na(english_words_frequency$Rank) &
english_words_frequency$Rank <= FREQ_X,
]
english_words_frequency$Word <- tolower(
as.character(english_words_frequency$Word)
)
english_words_frequency <- rbind(
english_words_frequency,
c(501, "can't", NA, 1),
c(502, "wasn't", NA, 1),
c(503, "don't", NA, 1),
c(504, "didn't", NA, 1),
c(505, "you're", NA, 1),
c(505, "youre", NA, 1),
c(506, "himself", NA, 1),
c(507, "that's", NA, 1),
c(508, "ender's", NA, 1),
c(509, "thats", NA, 1),
c(510, "didnt", NA, 1),
c(511, "began", NA, 1),
c(512, "didnt", NA, 1),
c(513, "there's", NA, 1),
c(514, "she's", NA, 1),
c(515, "theyd", NA, 1),
c(516, "wasnt", NA, 1),
c(517, "didnt", NA, 1),
c(518, "couldnt", NA, 1),
c(519, "nietzsche", NA, 1),
c(520, "aafvfv", NA, 1),
c(521, "wants", NA, 1),
c(522, "themselves", NA, 1),
c(523, "what's", NA, 1),
c(524, "qa'gwgwa", NA, 1),
c(525, "we're", NA, 1),
c(526, "isn't", NA, 1),
c(527, "runciter's", NA, 1),
c(528, "couldn't", NA, 1),
c(529, "they're", NA, 1),
c(530, "jeffs", NA, 1),
c(531, "hadnt", NA, 1),
c(532, "hadn't", NA, 1),
c(533, "aarfy", NA, 1)
)
epub_to_words <- function(filename){
data_words <- paste0(
system2(PATH_TO_PYSCRIPT, args=shQuote(filename), stdout=TRUE)
)
words <- read.table(header=TRUE, text=data_words, sep=",", quote="")
words$Word <- tolower(words$Word)
words$Count <- as.numeric(words$Count)
words <- words[!(words$Word %in% english_words_frequency$Word),]
words <- words[nchar(as.character(words$Word)) > 4,]
words$Word <- toupper(words$Word)
words
}
wordcloud_wrap <- function(author, title){
set.seed(43121)
words <- epub_to_words(booklist$Filename[
booklist$Author == author & booklist$Title == title
])
wordcloud(words$Word, words$Count, scale=c(10,.5), min.freq=3, max.words=20)
words
}
words <- wordcloud_wrap("Douglas Adams", "Hitchhiker's Guide to the Galaxy")

words <- wordcloud_wrap("Friedrich Nietzsche", "Thus Spoke Zarathustra")

words <- wordcloud_wrap("George Orwell", "1984")

words <- wordcloud_wrap("Robert Anton Wilson & Robert Shea", "Illuminatus! Trilogy")

words <- wordcloud_wrap("Philip K. Dick", "Ubik")

words <- wordcloud_wrap("Philip K. Dick", "Do Android Dream of Electric Sheep")

words <- wordcloud_wrap("Frank Herbert", "Dune")

words <- wordcloud_wrap("Orson Scott Card", "Ender's Game")

words <- wordcloud_wrap("Joseph Heller", "Catch-22")

words <- wordcloud_wrap("Ken Kesey", "One Flew Over the Cuckoo's Nest")

words <- wordcloud_wrap("Ken Grimwood", "Replay")

20+ hours manual editing in Gimp to make the words not fall down in places, also using multi-layered merges for some layers of the final cut.
(front-to-back)